🌐Web Technologies & APIs

How does the Internet work?
The Internet is the backbone of the Web, the technical infrastructure that makes the Web possible. At its most basic, the Internet is a large network of computers which communicate all together.
The history of the Internet is somewhat obscure. It began in the 1960s as a US-army-funded research project, then evolved into a public infrastructure in the 1980s with the support of many public universities and private companies. The various technologies that support the Internet have evolved over time, but the way it works hasn't changed that much: Internet is a way to connect computers all together and ensure that, whatever happens, they find a way to stay connected.
Important terms of Web Technology
Web page
HTML
Web Server
Web Browser
URL
Protocol
Internet Protocol (IP) Address
HTTP
XML
Gateway
API
What is Web Server?
The term web server can refer to hardware or software, or both of them working together.
On the hardware side, a web server is a computer that stores web server software and a website's component files (for example, HTML documents, images, CSS stylesheets, and JavaScript files). A web server connects to the Internet and supports physical data interchange with other devices connected to the web.
On the software side, a web server includes several parts that control how web users access hosted files. At a minimum, this is an HTTP server. An HTTP server is software that understands URLs (web addresses) and HTTP (the protocol your browser uses to view webpages). An HTTP server can be accessed through the domain names of the websites it stores, and it delivers the content of these hosted websites to the end user's device.
At the most basic level, whenever a browser needs a file that is hosted on a web server, the browser requests the file via HTTP. When the request reaches the correct (hardware) web server, the (software) HTTP server accepts the request, finds the requested document, and sends it back to the browser, also through HTTP. (If the server doesn't find the requested document, it returns a 404 response instead.)

To publish a website, you need either a static or a dynamic web server.
A static web server, or stack, consists of a computer (hardware) with an HTTP server (software). We call it "static" because the server sends its hosted files as-is to your browser.
A dynamic web server consists of a static web server plus extra software, most commonly an application server and a database. We call it "dynamic" because the application server updates the hosted files before sending content to your browser via the HTTP server.
For example, to produce the final webpages you see in the browser, the application server might fill an HTML template with content from a database. Sites like MDN or Wikipedia have thousands of webpages. Typically, these kinds of sites are composed of only a few HTML templates and a giant database, rather than thousands of static HTML documents. This setup makes it easier to maintain and deliver the content.
What is URL?
With Hypertext and HTTP, URL is one of the key concepts of the Web. It is the mechanism used by browsers to retrieve any published resource on the web.
URL stands for Uniform Resource Locator. A URL is nothing more than the address of a given unique resource on the Web. In theory, each valid URL points to a unique resource. Such resources can be an HTML page, a CSS document, an image, etc. In practice, there are some exceptions, the most common being a URL pointing to a resource that no longer exists or that has moved. As the resource represented by the URL and the URL itself are handled by the Web server, it is up to the owner of the web server to carefully manage that resource and its associated URL.
Basics: anatomy of a URL
Here are some examples of URLs:
Any of those URLs can be typed into your browser's address bar to tell it to load the associated page (resource).
A URL is composed of different parts, some mandatory and others optional. The most important parts are highlighted on the URL below (details are provided in the following sections):

Note: You might think of a URL like a regular postal mail address: the scheme represents the postal service you want to use, the domain name is the city or town, and the port is like the zip code; the path represents the building where your mail should be delivered; the parameters represent extra information such as the number of the apartment in the building; and, finally, the anchor represents the actual person to whom you've addressed your mail.
Note: There are some extra parts and some extra rules regarding URLs, but they are not relevant for regular users or Web developers. Don't worry about this, you don't need to know them to build and use fully functional URLs.
Scheme

The first part of the URL is the scheme, which indicates the protocol that the browser must use to request the resource (a protocol is a set method for exchanging or transferring data around a computer network). Usually for websites the protocol is HTTPS or HTTP (its unsecured version). Addressing web pages requires one of these two, but browsers also know how to handle other schemes such as mailto: (to open a mail client), so don't be surprised if you see other protocols.
Authority

Next follows the authority, which is separated from the scheme by the character pattern ://. If present the authority includes both the domain (e.g. www.example.com) and the port (80), separated by a colon:
The domain indicates which Web server is being requested. Usually this is a domain name, but an IP address may also be used (but this is rare as it is much less convenient).
The port indicates the technical "gate" used to access the resources on the web server. It is usually omitted if the web server uses the standard ports of the HTTP protocol (80 for HTTP and 443 for HTTPS) to grant access to its resources. Otherwise it is mandatory.
Note: The separator between the scheme and authority is ://. The colon separates the scheme from the next part of the URL, while // indicates that the next part of the URL is the authority.
One example of a URL that doesn't use an authority is the mail client (mailto:foobar). It contains a scheme but doesn't use an authority component. Therefore, the colon is not followed by two slashes and only acts as a delimiter between the scheme and mail address.
Path to resource

/path/to/myfile.html is the path to the resource on the Web server. In the early days of the Web, a path like this represented a physical file location on the Web server. Nowadays, it is mostly an abstraction handled by Web servers without any physical reality.
Parameters

?key1=value1&key2=value2 are extra parameters provided to the Web server. Those parameters are a list of key/value pairs separated with the & symbol. The Web server can use those parameters to do extra stuff before returning the resource. Each Web server has its own rules regarding parameters, and the only reliable way to know if a specific Web server is handling parameters is by asking the Web server owner.
Anchor

#SomewhereInTheDocument is an anchor to another part of the resource itself. An anchor represents a sort of "bookmark" inside the resource, giving the browser the directions to show the content located at that "bookmarked" spot. On an HTML document, for example, the browser will scroll to the point where the anchor is defined; on a video or audio document, the browser will try to go to the time the anchor represents. It is worth noting that the part after the #, also known as the fragment identifier, is never sent to the server with the request.
What is HTTP?
The Hypertext Transfer Protocol (HTTP) is an application-level protocol for distributed, collaborative, hypermedia information systems. This is the foundation for data communication for the World Wide Web (i.e. internet) since 1990. HTTP is a generic and stateless protocol which can be used for other purposes as well using extensions of its request methods, error codes, and headers.
Basically, HTTP is a TCP/IP based communication protocol, that is used to deliver data (HTML files, image files, query results, etc.) on the World Wide Web. The default port is TCP 80, but other ports can be used as well. It provides a standardized way for computers to communicate with each other. HTTP specification specifies how clients' request data will be constructed and sent to the server, and how the servers respond to these requests.
Basic Architecture
The following diagram shows a very basic architecture of a web application and depicts where HTTP sits:

The HTTP protocol is a request/response protocol based on the client/server based architecture where web browsers, robots and search engines, etc. act like HTTP clients, and the Web server acts as a server.
Client
The HTTP client sends a request to the server in the form of a request method, URI, and protocol version, followed by a MIME-like message containing request modifiers, client information, and possible body content over a TCP/IP connection.
Server
The HTTP server responds with a status line, including the message's protocol version and a success or error code, followed by a MIME-like message containing server information, entity meta information, and possible entity-body content.
HTTP Request Methods
The internet boasts a vast array of resources hosted on different servers. For you to access these resources, your browser needs to be able to send a request to the servers and display the resources for you. HTTP (Hypertext Transfer Protocol), is the underlying format that is used to structure request and responses for effective communication between a client and a server. The message that is sent by a client to a server is what is known as an HTTP request. When these requests are being sent, clients can use various methods.
Therefore, HTTP request methods are the assets that indicate the specific desired action to be performed on a given resource. Each method implements a distinct semantic, but there are some standard features shared by the various HTTP request methods.

What Are HTTP Request Methods?
An HTTP request is an action to be performed on a resource identified by a given Request-URL. Request methods are case-sensitive and should always be noted in upper case. There are various HTTP request methods, but each one is assigned a specific purpose.
How Do HTTP Requests Work?
HTTP requests work as the intermediary transportation method between a client/application and a server. The client submits an HTTP request to the server, and after internalizing the message, the server sends back a response. The response contains status information about the request.
What Are the Various Types of HTTP Request Methods?
GET
GET is used to retrieve and request data from a specified resource in a server. GET is one of the most popular HTTP request techniques. In simple words, the GET method is used to retrieve whatever information is identified by the Request-URL.
POST
Another popular HTTP request method is POST. In web communication, POST requests are utilized to send data to a server to create or update a resource. The information submitted to the server with POST request method is archived in the request body of the HTTP request. The HTTP POST method is often used to send user-generated data to a server. One example is when a user uploads a profile photo.
PUT
PUT is similar to POST as it is used to send data to the server to create or update a resource. The difference between the two is that PUT requests are idempotent. This means that if you call the same PUT requests multiple times, the results will always be the same.
DELETE
Just as it sounds, the DELETE request method is used to delete resources indicated by a specific URL. Making a DELETE request will remove the targeted resource.
There are many more HTTP request types. Check out this link for the full list.
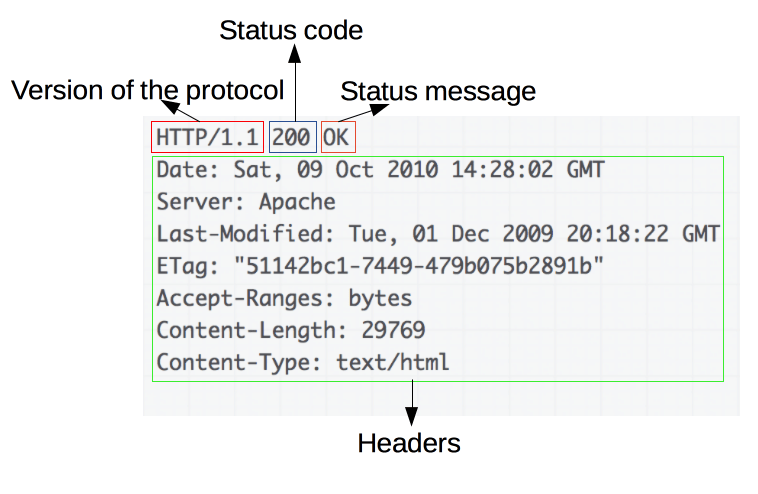
HTTP Responses and Status Codes
An example response:
Responses consist of the following elements:
The version of the HTTP protocol they follow.
A status code, indicating if the request was successful or not, and why.
A status message, a non-authoritative short description of the status code.
HTTP headers, like those for requests.
Optionally, a body containing the fetched resource.
Here's the details of all the HTTP status codes:
APIs (Application Programming Interfaces)
An Application Programming Interface (API) is a web service that grants access to specific data and methods that other applications can access – and sometimes edit – via standard HTTP protocols, just like a website. This simplicity makes it easy to quickly integrate APIs into a wide variety of applications. REpresentational State Transfer (REST), is probably the most popular architectural style of APIs for web services. It consists of a set of guidelines designed to simplify client / server communication. REST APIs make data access much more straightforward and logical.
How an API works
An API is a set of defined rules that explain how computers or applications communicate with one another. (Typically these rules are documented in an API specification). APIs sit between an application and the web server, acting as an intermediary layer that processes data transfer between systems.
Here’s how an API works:
A client application initiates an API call to retrieve information—also known as a request. This request is processed from an application to the web server via the API’s Uniform Resource Identifier (URI) and includes a request verb, headers, and sometimes, a request body.
After receiving a valid request, the API makes a call to the external program or web server.
The server sends a response to the API with the requested information.
The API transfers the data to the initial requesting application.
While the data transfer will differ depending on the web service being used, this process of requests and response all happens through an API. Whereas a graphical user interface provides humans access to an application’s data and functionality, an API provides that access to computers or other applications.
APIs offer security by design because their position as middleman facilitates the abstraction of functionality between two systems—the API endpoint decouples the consuming application from the infrastructure providing the service. API calls usually include authorization credentials to reduce the risk of attacks on the server, and an API gateway can limit access to minimize security threats. Also, during the exchange, HTTP headers, cookies, or query string parameters provide additional security layers to the data.
For example, consider an API offered by a payment processing service. Customers can enter their card details on the frontend of an application for an ecommerce store. The payment processor doesn’t require access to the user’s bank account; the API creates a unique token for this transaction and includes it in the API call to the server. This ensures a higher level of security against potential hacking threats.
The Request
When you want to interact with data via a REST API, this is called a request. A request is made up of the following components:
Endpoint – The URL that delineates what data you are interacting with. Similar to how a web page URL is tied to a specific page, an endpoint URL is tied to a specific resource within an API.
Method – Specifies how you’re interacting with the resource located at the provided endpoint. REST APIs can provide methods to enable full Create, Read, Update, and Delete (CRUD) functionality. Here are common methods most REST APIs provide:
GET – Retrieve data
PUT – Replace data
POST – Create data
DELETE – Delete data
Data – If you’re using a method that involves changing data in a REST API, you’ll need to include a data payload with the request that includes all data that will be created or modified.
Headers – Contain any metadata that needs to be included with the request, such as authentication tokens, the content type that should be returned, and any caching policies.
The Response
When you perform a request, you’ll get a response from the API. Just like in the request, it’ll have a response header and response data, if applicable. The response header consists of useful metadata about the response, while the response data returns what you actually requested. This can be any sort of data, as it’s really dependent on the API. The text is usually returned as JSON, but other markdown languages like XML are also possible.
Let’s look at a simple example of a request and a response. In the terminal, we’ll use curl to make a GET request to the Open Notify API. This is a simple, yet nifty API that has information about astronauts that are currently in space:
You should see a response in JSON format that lists data about these astronauts, at the time of this article there are three people on a historic trip to the International Space Station:
Types of API protocols
As the use of web APIs has increased, certain protocols have been developed to provide users with a set of defined rules that specifies the accepted data types and commands. In effect, these API protocols facilitate standardized information exchange:
SOAP (Simple Object Access Protocol) is an API protocol built with XML, enabling users to send and receive data through SMTP and HTTP. With SOAP APIs, it is easier to share information between apps or software components that are running in different environments or written in different languages.
XML-RPC is a protocol that relies on a specific format of XML to transfer data, whereas SOAP uses a proprietary XML format. XML-RPC is older than SOAP, but much simpler, and relatively lightweight in that it uses minimum bandwidth.
JSON-RPC is a protocol similar to XML-RPC, as they are both remote procedure calls (RPCs), but this one uses JSON instead of XML format to transfer data. Both protocols are simple. While calls may contain multiple parameters, they only expect one result.
REST (Representational State Transfer) is a set of web API architecture principles, which means there are no official standards (unlike those with a protocol). To be a REST API (also known as a RESTful API), the interface must adhere to certain architectural constraints. It’s possible to build RESTful APIs with SOAP protocols, but the two standards are usually viewed as competing specifications.
Common API examples
Because APIs allow companies to open up access to their resources while maintaining security and control, they have become a valuable aspect of modern business. Here are some popular examples of application programming interfaces you may encounter:
Universal logins: A popular API example is the function that enables people to log in to websites by using their Facebook, Twitter, or Google profile login details. This convenient feature allows any website to leverage an API from one of the more popular services to quickly authenticate the user, saving them the time and hassle of setting up a new profile for every website service or new membership.
Third-party payment processing: For example, the now-ubiquitous "Pay with PayPal" function you see on ecommerce websites works through an API. This allows people to pay for products online without exposing any sensitive data or granting access to unauthorized individuals.
Travel booking comparisons: Travel booking sites aggregate thousands of flights, showcasing the cheapest options for every date and destination. This service is made possible through APIs that provide application users with access to the latest information about availability from hotels and airlines. With an autonomous exchange of data and requests, APIs dramatically reduce the time and effort involved in checking for available flights or accommodation.
Google Maps: One of the most common examples of a good API is the Google Maps service. In addition to the core APIs that display static or interactive maps, the app utilizes other APIs and features to provide users with directions or points of interest. Through geolocation and multiple data layers, you can communicate with the Maps API when plotting travel routes or tracking items on the move, such as a delivery vehicle.
Twitter: Each Tweet contains descriptive core attributes, including an author, a unique ID, a message, a timestamp when it was posted, and geolocation metadata. Twitter makes public Tweets and replies available to developers and allows developers to post Tweets via the company's API.
Check these APIs for getting more familiar with it!
Fundamentals of Web Development
In the section below you'll be introduced to the fundamental components of web development and get familiar with the technologies used in creating web applications.
What is HTML?
HTML stands for Hyper Text Markup Language. It is a standard markup language for web page creation. It allows the creation and structure of sections, paragraphs, and links using HTML elements (the building blocks of a web page) such as tags and attributes.
HTML has a lot of use cases, namely:
Web development. Developers use HTML code to design how a browser displays web page elements, such as text, hyperlinks, and media files.
Internet navigation. Users can easily navigate and insert links between related pages and websites as HTML is heavily used to embed hyperlinks.
Web documentation. HTML makes it possible to organize and format documents, similarly to Microsoft Word.
It’s also worth noting that HTML is not considered a programming language as it can’t create dynamic functionality. It is now considered an official web standard. The World Wide Web Consortium (W3C) maintains and develops HTML specifications, along with providing regular updates.

The
<!DOCTYPE html>declaration defines that this document is an HTML5 documentThe
<html>element is the root element of an HTML pageThe
<head>element contains meta information about the HTML pageThe
<title>element specifies a title for the HTML page (which is shown in the browser's title bar or in the page's tab)The
<body>element defines the document's body, and is a container for all the visible contents, such as headings, paragraphs, images, hyperlinks, tables, lists, etc.The
<h1>element defines a large headingThe
<p>element defines a paragraph
What is CSS?
CSS stands for Cascading Style Sheets.
CSS describes how HTML elements are to be displayed. We use CSS to stylize and add "make-up" to our HTML files which we use to build web pages.
You can also check out this W3Schools page to learn more about CSS.
What is JavaScript?
JavaScript is the programming language used for making web pages interactive. Without JavaScript web pages would be static (only words with styled format). Thanks to JavaScript we can add many functionalities to the web pages and turn those static web pages into full-blown web applications.
Here's a link to a short introduction to JavaScript.
What is Front End?

{kind=link}
What is Back End?
Last updated