🗄️Introduction to Databases & SQL
Introduction to Databases
Prerequisites
The prerequisite for this week is to have PostgreSQL installed on your computer before coming to class. You can find instructions for this in the PostgreSQL Installation section below.
What is a Database?
A database is a data structure that stores organized information. For example, Google stores data about roads and provides directions to get from one location to another by driving through the Maps application. Facebook stores the user data in a database, and so does Twitter or any other social media platform. A single sentence definition would be: "Databases are tools that are used to store and retrieve information."
In simple words, data can be facts related to any object in consideration. For example, your name, age, height, weight, etc. are some data related to you. A picture, image, file, pdf, etc. can also be considered data.
A database is a systematic collection of data. They support electronic storage and manipulation of data. Databases make data management easy.
Let us discuss a database example: An online telephone directory uses a database to store data of people, phone numbers, and other contact details. Your electricity service provider uses a database to manage billing, client-related issues, handle fault data, etc.
Let us also consider Facebook. It needs to store, manipulate, and present data related to members, their friends, member activities, messages, advertisements, and a lot more. We can provide countless examples of the usage of databases.
Most databases contain multiple tables, which may each include several different fields. For example, a company database may include tables for products, employees, and financial records. Each of these tables would have different fields that are relevant to the information stored in the table. But don't worry! We will explain these terms as we go along.
What are The Database Types?
There are multiple database types. The best database for a specific organization depends on how the organization intends to use the data. Please take a look at some of the different database types below.
⚠️ Do not try and memorize these types! As you go on with coding, you will grow a better sense of understanding regarding different database types. So relax, just read about these different database types and keep in mind that for different needs, there are different solutions. (https://www.youtube.com/watch?v=W2Z7fbCLSTw)
Relational databases ➡️ A relational database is structured, meaning the data is organized in tables. Many times, the data within these tables have relationships with one another or dependencies. Items in a relational database are organized as a set of tables with columns and rows. Relational database technology provides the most efficient and flexible way to access structured information.

NoSQL databases ➡️ A NoSQL, or nonrelational database, allows unstructured and semistructured data to be stored and manipulated (in contrast to a relational database, which defines how all data inserted into the database must be composed). A non relational database is document-oriented, meaning, all information gets stored in more of a laundry list order. Within a single construct, or document, you will have all of your data listed out. NoSQL databases grew popular as web applications became more common and more complex.

Object-oriented databases ➡️ Information in an object-oriented database is represented in the form of objects, as in object-oriented programming.
Distributed databases ➡️ A distributed database consists of two or more files located on different sites. The database may be stored on multiple computers, located in the same physical location, or scattered over different networks.
Data warehouses ➡️ A central repository for data, a data warehouse is a type of database specifically designed for fast query and analysis.
Graph databases ➡️ A graph database stores data in terms of entities and the relationships between entities.
OLTP databases ➡️ An OLTP database is a speedy, analytic database designed for large numbers of transactions performed by multiple users.
The most popularly used DBMS types are SQL and No-SQL databases. Here is a comparison: https://www.integrate.io/blog/the-sql-vs-nosql-difference/
What is Database Management System (DBMS)?
A database typically requires a comprehensive database software program known as a database management system (DBMS). A DBMS serves as an interface between the database and its end-users or programs, allowing users to retrieve, update, and manage how the information is organized and optimized. A DBMS also facilitates oversight and control of databases, enabling a variety of administrative operations such as performance monitoring, tuning, and backup and recovery.
Here is the list of some popular DBMS systems:
SQL DBMS (Relational)
PostgreSQL, MySQL, and SQLite
No-SQL DBMS (Non-relational)
Relational Databases Explained 🤓
A relational database is the most common type of database. It uses a structure that allows us to identify and access data in relation to another piece of data in the database. Often, data in a relational database is organized into tables. "What are the tables?" we hear you asking. Good question. Just read below.
Tables: Rows and Columns
Tables can have hundreds, thousands, and sometimes even millions of rows of data. These rows are often called records.
Tables can also have many columns of data. Columns are labeled with a descriptive name (say, age for example) and have a specific data type.
For example, a column called age may have a type of INTEGER (denoting the type of data it is meant to hold).

In the table above, there are three columns:
name, age, and country.
The name and country columns store string data types, whereas age stores integer data types. The set of columns and data types make up the schema of this table.
The table also has four rows, or records, in it (one each for Natalia, Ned, Zenas, and Laura).
OK, now that we have thrown some terms in your way, let's wrap them up and explain them all!
Terms
Entity
An entity is a table in a database. It is described using an Entity-Relationship Diagram, which is a type of graphic that shows the relationships among database tables.
Index
An index is a data structure that helps speed database queries for large datasets. Database developers create an index on particular columns in a table. The index holds the column values but just pointers to the data in the rest of the table and can be searched efficiently and quickly.
Key
A key is a value used to identify a record in a table uniquely. A key could be a single column or a combination of multiple columns. Keys help enforce data integrity and avoid duplication. The main types of keys used in a database are:
Candidate keys
The set of columns that can each uniquely identify a record and from which the primary key is chosen.
Primary Key

This key uniquely identifies a record in a table. It has the following attributes:
A primary key cannot be NULL
A primary key value must be unique
The primary key values should rarely be changed
The primary key must be given a value when a new record is inserted
Composite Key
A composite key is a primary key composed of multiple columns used to identify a record uniquely.

In our database, we have two people with the same name Robert Phil, but they live in different places. Hence, we require both Full Name and Address to identify a record uniquely. That is a composite key.
Foreign Key

The key links a record to a record in another table. A table's foreign key must exist as the primary key of another table and it helps to connect your tables. It has the following attributes:
A foreign key can have a different name from its primary key
It ensures rows in one table have corresponding rows in another
Unlike the Primary key, they do not have to be unique. Most often they aren't
Foreign keys can be null even though primary keys can not

Why do you need a foreign key?

You will only be able to insert values into your foreign key that exist in the unique key in the parent table. The above problem can be overcome by declaring the membership ID from Table 2 as the foreign key of the membership ID from Table 1. Now, if somebody tries to insert a value in the membership ID field that does not exist in the parent table, an error will be shown!
Query
A database query is usually written in SQL and can be either a select query or an action query. A select query requests data from a database; an action query changes, updates, or adds data. Here's an example:
Schema
A database schema is the design of tables, columns, relations, and constraints that make up a logically distinct section of a database.

SQL Data Types
Each column in a database table is required to have a name and a data type.
An SQL developer must decide what type of data will be stored inside each column when creating a table. The data type is a guideline for SQL to understand what type of data is expected inside each column, and it also identifies how SQL will interact with the stored data.
Note: Data types might have different names in different databases. And even if the name is the same, the size and other details may be different! Always check the documentation!
You can check the official documentation for the PostgreSQL data types from the following link: https://www.postgresql.org/docs/9.5/datatype.html
You can check the following tutorial to learn about different data types and their uses in SQL with the help of examples: https://www.programiz.com/sql/data-types
Normalization
When a database is described as relational, it has been designed to conform (at least mostly) to a set of practices called the rules of normalization. A normalized database is one that follows the rules of normalization.
Normalization is the process of efficiently organizing data in a database. To normalize a database is to design its tables (relations) and columns (attributes) in a way to ensure data integrity (only storing related data in a table) and to avoid duplication (for example, storing the same data in more than one table). Normalization rules divide larger tables into smaller tables and link them using relationships. The primary levels of normalization are:
1NF (First Normal Form)
2NF (Second Normal Form)
3NF (Third Normal Form)
Database Normalization can be easily understood with the following case study. Assume, a video library maintains a database of movies rented out. Without any normalization in database, all information is stored in one table as shown below.

Here you see Movies Rented column has multiple values. Now let's move into 1st Normal Forms:
1NF (First Normal Form) Rules
Rule 1 - Each table cell should contain a single value.
Rule 2 - Each record needs to be unique.
The below table is in 1NF.

2NF (Second Normal Form) Rules
Rule 1 - Be in 1NF
Rule 2 - Single Column Primary Key
It is clear that we can't move forward to make our simple database in the 2nd Normalization form unless we partition the table above.


We have divided our 1NF table into two tables viz. Table 1 and Table2. Table 1 contains member information. Table 2 contains information on movies rented.
We have introduced a new column called Membership ID which is the primary key for Table 1. Records can be uniquely identified in Table 1 using the Membership ID.
What are transitive functional dependencies?
A transitive functional dependency is when changing a non-key column, might cause any of the other non-key columns to change
Consider Table 1. Changing the non-key column Full Name may change Salutation.

3NF (Third Normal Form) Rules
Rule 1 - Be in 2NF
Rule 2 - Has no transitive functional dependencies
To move our 2NF table into 3NF, we again need to again divide our table.
3NF Example
Below is a 3NF example in an SQL database:



We have again divided our tables and created a new table that stores Salutations.
There are no transitive functional dependencies, and hence our table is in 3NF.
In Table 3 Salutation ID is the primary key, and in Table 1 Salutation ID is foreign to the primary key in Table 3.
Database Relationships
Relationships allow you to describe the connections between different database tables in powerful ways. These relationships can then be leveraged to perform powerful cross-table queries, known as joins.
Types of Database Relationships
There are three types of database relationships, each named according to the number of table rows involved in the relationship. Each of these three relationship types exists between two tables.
One-to-one relationships occur when each entry in the first table has one, and only one, counterpart in the second table. One-to-one relationships are rarely used because it is often more efficient to put all the information in a single table. Some database designers take advantage of this relationship by creating tables that contain a subset of the data from another table.
One-to-many relationships are the most common type of database relationship. They occur when each record in Table A corresponds to one or more records in Table B, but each record in Table B corresponds to only one record in Table A. For example, the relationship between a Teachers table and a Students table in an elementary school database would likely be a one-to-many relationship because each student has only one teacher, but each teacher has several students. This one-to-many design helps eliminate duplicated data.
Many-to-many relationships occur when each record in Table A corresponds to one or more records in Table B, and each record in Table B corresponds to one or more records in Table A. For example, the relationship between a Teachers and a Courses table would likely be many-to-many because each teacher may instruct more than one course, and each course may have more than one instructor.
Creating Relationships With Foreign Keys
You create relationships between tables by specifying a foreign key. This key tells the relational database how the tables are related. In many cases, a column in Table A contains primary keys that are referenced from Table B.
Consider the example of the Teachers and Students tables. The Teachers table contains just an ID, a name, and a course column:

The Students table includes an ID, name, and a foreign key column:

The column Teacher_FK in the Students table references the primary key value of an instructor in the Teachers table. Frequently, database designers use "PK" or "FK" in the column name to easily identify a primary key or foreign key column.
These two tables illustrate a one-to-many relationship between the teachers and the students.
ACID Properties
The ACID model of database design enforces data integrity through:
Atomicity: Each database transaction must follow an all-or-nothing rule, meaning that if any part of the transaction fails, the entire transaction fails.
Consistency: Each database transaction must follow all the database's defined rules; any transaction that would violate these rules is not allowed.
Isolation: Each database transaction will occur independently of any other transaction. For example, if multiple transactions are submitted concurrently, the database will prevent any interference between them.
Durability: Each database transaction will permanently exist despite any database failure, through backups or other means.
Check out this article for a detailed explanation of ACID with examples.
Entity Relationship Diagram (ERD)
Database is absolutely an integral part of software systems. To fully utilize ERD in database engineering guarantees you to produce high-quality database design to use in database creation, management, and maintenance. An ERD also provides a means for communication.
What is an ERD?
Entity Relationship Diagram, also known as ERD, is a type of structural diagram for use in database design. An ERD contains different symbols and connectors that visualize two important pieces of information: The major entities within the system scope, and the inter-relationships among these entities. And that's why it's called an "Entity" "Relationship" diagram (ERD)!
In a typical ERD, you can find symbols such as rounded rectangles and connectors (with different styles of their ends) that depict the entities, their attributes, and inter-relationships.
ERD notations guide
An ERD contains entities, attributes, and relationships. In this section, we will go through the ERD symbols in detail.
There are several relationship notations used in ERDs. Below is an image of "Crow's Foot" notation — a popular one. 🐦

Entity
An ERD entity is a definable thing or concept within a system, such as a person/role (e.g. Student), object (e.g. Invoice), concept (e.g. Profile) or event (e.g. Transaction) (note: In ERD, the term "entity" is often used instead of "table", but they are the same). When determining entities, think of them as nouns. In ER models, an entity is shown as a rounded rectangle, with its name on top and its attributes listed in the body of the entity shape. The ERD example below shows an example of an ER entity.

Entity Attributes
Also known as a column, an attribute is a property or characteristic of the entity that holds it.
An attribute has a name that describes the property and a type that describes the kind of attribute it is, such as varchar for a string, and int for integer. When an ERD is drawn for physical database development, it is important to ensure the use of types that are supported by the target RDBMS.
The ER diagram example below shows an entity with some attributes in it.
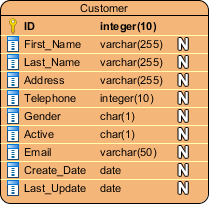
Primary Key
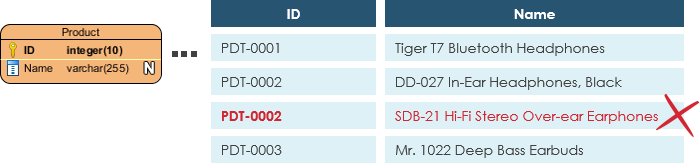
Also known as PK, a primary key is a special kind of entity attribute that uniquely defines a record in a database table. In other words, there must not be two (or more) records that share the same value for the primary key attribute. The ERD example below shows an entity 'Product' with a primary key attribute 'ID', and a preview of table records in the database. The third record is invalid because the value of ID 'PDT-0002' is already used by another record.
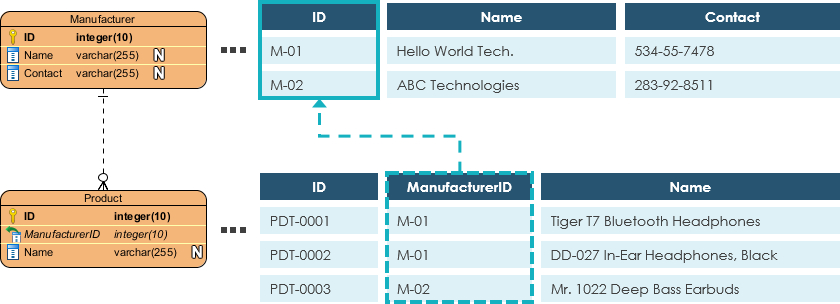
Foreign Key
Also known as FK, a foreign key is a reference to a primary key in a table. It is used to identify the relationships between entities. Note that foreign keys need not be unique. Multiple records can share the same values. The ER Diagram example below shows an entity with some columns, among which a foreign key is used in referencing another entity.
Relationship
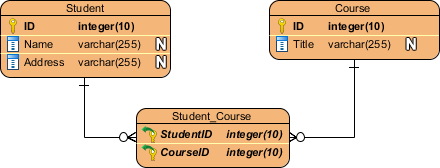
A relationship between two entities signifies that the two entities are associated with each other somehow. For example, a student might enroll in a course. The entity Student is therefore related to Course, and a relationship is presented as a connector connecting between them.
Cardinality
Cardinality defines the possible number of occurrences in one entity which is associated with the number of occurrences in another. For example, ONE team has MANY players. When present in an ERD, the entity Team and Player are inter-connected with a one-to-many relationship.
In an ER diagram, cardinality is represented as a crow's foot at the connector's ends. The three common cardinal relationships are one-to-one, one-to-many, and many-to-many.
One-to-One cardinality example
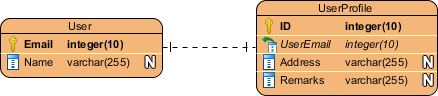
A one-to-one relationship is mostly used to split an entity in two to provide information concisely and make it more understandable. The figure below shows an example of a one-to-one relationship.
One-to-Many cardinality example
A one-to-many relationship refers to the relationship between two entities X and Y in which an instance of X may be linked to many instances of Y, but an instance of Y is linked to only one instance of X. The figure below shows an example of a one-to-many relationship.

Many-to-Many cardinality example
A many-to-many relationship refers to the relationship between two entities X and Y in which X may be linked to many instances of Y and vice versa. The figure below shows an example of a many-to-many relationship. Note that a many-to-many relationship is split into a pair of one-to-many relationships in a physical ERD. You will know what a physical ERD is in the next section.
Useful Links
If you find it difficult to get started with drawing an ERD, you can check the following tutorial: https://www.gliffy.com/blog/how-to-draw-an-entity-relationship-diagram
For more Entity Relationship Diagram examples, see https://circle.visual-paradigm.com/category/system-design-development/entity-relationship-diagram/
In order to draw ERD for class exercises and homeworks you can use pgadmin ERD tool or dbdesigner
Introduction to SQL
What is SQL?
SQL (Structured Query Language) is a programming language used to communicate with data stored in a relational database management system.
Many relational database management systems (RDBMS) use SQL (and variations of SQL) to access the data in tables. For example, SQLite is a relational database management system. SQLite contains a minimal set of SQL commands (which are the same across all RDBMSs). Other RDBMSs may use other variants.
SQL is often pronounced in one of two ways. You can pronounce it by speaking each letter individually like “S-Q-L”, or pronounce it using the word “sequel”.
What Can SQL do?
SQL can execute queries against a database
SQL can retrieve data from a database
SQL can insert records in a database
SQL can update records in a database
SQL can delete records from a database
SQL can create new databases
SQL can create new tables in a database
SQL can create stored procedures in a database
SQL can create views in a database
SQL can set permissions on tables, procedures, and views
SQL is a Standard - BUT...
Although SQL is an ANSI/ISO standard, there are different versions of the SQL language.
However, to be compliant with the ANSI standard, they all support at least the major commands (such as SELECT, UPDATE, DELETE, INSERT, WHERE) in a similar manner.
Note: Most of the SQL database programs also have their own proprietary extensions in addition to the SQL standard!
SQL Statements
Most of the actions you need to perform on a database are done with SQL statements.
The following SQL statement selects all the records in the "Customers" table:
SQL keywords are NOT case sensitive: select is the same as SELECT
Some of The Most Common SQL Commands
SELECT - extracts data from a database
UPDATE - updates data in a database
DELETE - deletes data from a database
INSERT INTO - inserts new data into a database
CREATE DATABASE - creates a new database
ALTER DATABASE - modifies a database
CREATE TABLE - creates a new table
ALTER TABLE - modifies a table
DROP TABLE - deletes a table
CREATE INDEX - creates an index (search key)
DROP INDEX - deletes an index
Please check this link and follow through the tutorials to get the basics of SQL commands and queries.
We will use PostgreSQL (a relational database management system) in our course. Let's learn more about PostgreSQL in the next section.
PostgreSQL
What is PostgreSQL?

Let’s start with a simple question: what is PostgreSQL?
PostgreSQL is an advanced, enterprise-class, and open-source relational database system. PostgreSQL supports both SQL (relational) and JSON (non-relational) querying.
PostgreSQL is a highly stable database backed by more than 20 years of development by the open-source community.
PostgreSQL is used as a primary database for many web applications as well as mobile and analytics applications.
History of PostgreSQL
The PostgreSQL project started in 1986 at Berkeley Computer Science Department, University of California.
The project was originally named POSTGRES, in reference to the older Ingres database which also developed at Berkeley. The goal of the POSTGRES project was to add the minimal features needed to support multiple data types.
In 1996, the POSTGRES project was renamed to PostgreSQL to clearly illustrate its support for SQL. Today, PostgreSQL is commonly abbreviated as Postgres.
Since then, the PostgreSQL Global Development Group, a dedicated community of contributors continues to make the releases of the open-source and free database project.
Originally, PostgreSQL was designed to run on UNIX-like platforms. And then, PostgreSQL was evolved run on various platforms such as Windows, macOS, and Solaris.
Common Use cases of PostgreSQL
The following are the common use cases of PostgreSQL.
1) A robust database in the LAPP stack
LAPP stands for Linux, Apache, PostgreSQL, and PHP (or Python and Perl). PostgreSQL is primarily used as a robust back-end database that powers many dynamic websites and web applications.
2) General purpose transaction database
Large corporations and startups alike use PostgreSQL as primary databases to support their applications and products.
3) Geospatial database
PostgreSQL with the PostGIS extension supports geospatial databases for geographic information systems (GIS).
Language support
PostgreSQL support most popular programming languages:
Python
Java
C#
C/C+
Ruby
JavaScript (Node.js)
Perl
Go
Tcl
Who uses PostgreSQL
Many companies have built products and solutions based on PostgreSQL. Some featured companies are Apple, Fujitsu, Red Hat, Cisco, Juniper Network, Instagram, etc.
PostgreSQL Installation
Please download PostgreSQL before coming to the lesson. Select the appropriate installer for your computer from the following link: https://www.postgresql.org/download/
!!! Please download the latest version available (PostgreSQL 14 at the time when this notebook is created)
You can follow this video for the installation (the process is the same for mac, you just need to install the mac installer from the website): https://www.youtube.com/watch?v=RAFZleZYxsc&ab_channel=ProgrammingKnowledge2
To get more insights about PostgreSQL and learn how to import databases etc. you can check the following website: https://www.postgresqltutorial.com/postgresql-getting-started/
Python and PostgreSQL
We will use psycopg database adapter in order to connect to the PostgreSQL database server in the Python program.
Install the psycopg2 module
Run the following command in your terminal:
pip install psycopg2
Create a new database
First, log in to the PostgreSQL database server using any client tool such as pgAdmin.
Second, use the following statement to create a new database named suppliers in the PostgreSQL database server.
CREATE DATABASE suppliers;
Connect to the PostgreSQL database using the psycopg2
To connect to the suppliers database, you use the connect() function of the psycopg2 module.
The connect() the function creates a new database session and returns a new instance of the connection class. By using the connection object, you can create a new cursor to execute any SQL statements.
To call the connect() function, you specify the PostgreSQL database parameters as a connection string and pass it to the function like this:
conn = psycopg2.connect("dbname=suppliers user=postgres password=postgres")
Or you can use a list of keyword arguments:
The following is the list of the connection parameters:
database: the name of the database that you want to connect.user: the username used to authenticate.password: password used to authenticate.host: database server address e.g., localhost or an IP address.port: the port number that defaults to 5432 if it is not provided.
To make it more convenient, you can use a configuration file to store all connection parameters.
The following shows the contents of the database.ini file:
[postgresql] host=localhost database=suppliers user=postgres password=SecurePas$1
By using the database.ini, you can change the PostgreSQL connection parameters when you move the code to the production environment without modifying the code.
Notice that if you git, you need to add the database.ini to the .gitignore file to not committing the sensitive information to the public repo like github. The .gitignore file will be like this:
database.ini
The following config() function read the database.ini file and returns connection parameters. The config() function is placed in the config.py file:
The following connect() function connects to the suppliers database and prints out the PostgreSQL database version.
How it works.
First, read database connection parameters from the
database.inifile.Next, create a new database connection by calling the
connect()function.Then, create a new
cursorand execute an SQL statement to get the PostgreSQL database version.After that, read the result set by calling the
fetchone()method of the cursor object.Finally, close the communication with the database server by calling the
close()method of thecursorandconnectionobjects.
Execute the connect.py file
To execute the connect.py file, you use the following command:
python connect.py
You will see the following output:
Connecting to the PostgreSQL database... PostgreSQL database version: ('PostgreSQL 12.3, compiled by Visual C++ build 1914, 64-bit',) Database connection closed.
It means that you have successfully connected to the PostgreSQL database server.
Troubleshooting
The connect() function raises the DatabaseError exception if an error occurred. To see how it works, you can change the connection parameters in the database.ini file.
For example, if you change the host to localhosts, the program will output the following message:
Connecting to the PostgreSQL database... could not translate host name "localhosts" to address: Unknown host
The following displays error message when you change the database to a database that does not exist e.g., supplier:
Connecting to the PostgreSQL database... FATAL: database "supplier" does not exist
If you change the user to postgres, it will not be authenticated successfully as follows:
Connecting to the PostgreSQL database... FATAL: password authentication failed for user "postgress"
In this tutorial, you have learned how to connect to the PostgreSQL database server from Python programs.
For this week, we have learned how you can connect to postgreql database from python code. Next week, you will learn more about SQL commands. After learning them, you can also check the following link to learn more about usage of those commands within the python code.

BONUS: SQL Injection 💉
A SQL injection attack is when a third party is able to use SQL commands to interfere with back-end databases in ways that they shouldn't be allowed to. This is generally the result of websites directly incorporating user-inputted text into a SQL query and then running that query against a database. How this works in a non-malicious context is that the user-inputted text is used to search the database - for example, logging in to a specific account by matching it based on the username and password entered by the user.
Please watch this video for a detailed explanation.
Please check this link about protecting against SQL injections. (You can also check the Python code samples within the article)
END OF THE LECTURE
Last updated