# Assignment
* [What is statistics?](https://goodboychan.github.io/python/datacamp/statistics/2020/08/26/01-Summary-Statistics-with-Python.html#What-is-statistics?)
* [Measures of center](https://goodboychan.github.io/python/datacamp/statistics/2020/08/26/01-Summary-Statistics-with-Python.html#Measures-of-center)
* [Mean and median](https://goodboychan.github.io/python/datacamp/statistics/2020/08/26/01-Summary-Statistics-with-Python.html#Mean-and-median)
* [Mean vs. median](https://goodboychan.github.io/python/datacamp/statistics/2020/08/26/01-Summary-Statistics-with-Python.html#Mean-vs.-median)
* [Measures of spread](https://goodboychan.github.io/python/datacamp/statistics/2020/08/26/01-Summary-Statistics-with-Python.html#Measures-of-spread)
* [Quartiles, quantiles, and quintiles](https://goodboychan.github.io/python/datacamp/statistics/2020/08/26/01-Summary-Statistics-with-Python.html#Quartiles,-quantiles,-and-quintiles)
* [Variance and standard deviation](https://goodboychan.github.io/python/datacamp/statistics/2020/08/26/01-Summary-Statistics-with-Python.html#Variance-and-standard-deviation)
* [Finding outliers using IQR](https://goodboychan.github.io/python/datacamp/statistics/2020/08/26/01-Summary-Statistics-with-Python.html#Finding-outliers-using-IQR)
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (10, 8)
```
### What is statistics?
* Statistics
* the practice and study of collecting and analyzing data
* Summary Statistic - A fact about or summary of some data
* Example
* How likely is someone to purchase a product? Are people more likely to purchase it if they can use a different payment system?
* How many occupants will your hotel have? How can you optimize occupancy?
* How many sizes of jeans need to be manufactured so they can fit 95% of the population? Should the same number of each size be produced?
* A/B tests: Which ad is more effective in getting people to purchase product?
* Type of statistics
* Descriptive statistics
* Describe and summarize data
* Inferential statistics
* Use a sample of data to make inferences about a larger population
* Type of data
* Numeric (Quantitative)
* Continuous (Measured)
* Discrete (Counted)
* Categorical (Qualitative)
* Nomial (Unordered)
* Ordinal (Ordered)
### Measures of center
#### Mean and median
In this module, you'll be working with the [2018 Food Carbon Footprint Index](https://www.nu3.de/blogs/nutrition/food-carbon-footprint-index-2018) from nu3. The `food_consumption` dataset contains information about the kilograms of food consumed per person per year in each country in each food category (`consumption`) as well as information about the carbon footprint of that food category (`co2_emissions`) measured in kilograms of carbon dioxide, or CO\_2CO2, per person per year in each country.
In this exercise, you'll compute measures of center to compare food consumption in the US and Belgium.
```
#read the data
#./dataset/ is a path. Copy and paste the path of the CSV file in your computer to read the data.
food_consumption = pd.read_csv('./dataset/food_consumption.csv', index_col=0)
food_consumption.head()
```
The output should look as follows;
| | country | food\_category | consumption | co2\_emission |
| - | --------- | -------------- | ----------- | ------------- |
| 1 | Argentina | pork | 10.51 | 37.20 |
| 2 | Argentina | poultry | 38.66 | 41.53 |
| 3 | Argentina | beef | 55.48 | 1712.00 |
| 4 | Argentina | lamb\_goat | 1.56 | 54.63 |
| 5 | Argentina | fish | 4.36 | 6.96 |
```
#filter for Belgium
be_consumption = food_consumption[food_consumption['country'] == 'Belgium']
# Filter for USA
usa_consumption = food_consumption[food_consumption['country'] == 'USA']
Q-1) Calculate mean and median consumption in Belgium
Q-2) Calculate mean and median consumption of USA
```
```
#Check if you did it correctly
42.132727272727266
12.59
44.650000000000006
14.58
```
or
# Work with both countries together
be_and_usa = food_consumption[(food_consumption['country'] == 'Belgium') |
(food_consumption['country'] == 'USA')]
# Q-3) Group by country, select consumption column, and compute mean and median
```
#Check if you did it correctly
mean median
country
Belgium 42.132727 12.59
USA 44.650000 14.58
```
#### Mean vs. median
You learned that the mean is the sum of all the data points divided by the total number of data points, and the median is the middle value of the dataset where 50% of the data is less than the median, and 50% of the data is greater than the median. In this exercise, you'll compare these two measures of center.
```
rice_consumption = food_consumption[food_consumption['food_category'] == 'rice']
Q-4)Plot the histogram of co2_emission for rice
Q-5) Calculate mean and median of co2_emission with .agg()
```
```
#Check if you did it correctly
mean 37.591615
median 15.200000
Name: co2_emission, dtype: float64
```
### Measures of spread
* Variance
* Average distance from each data point to the data's mean
* Standard deviation
* Mean absolute deviation
* Standard deviation vs. mean absolute deviation
* Standard deviation squares distances, penalizing longer distances more than shorter ones
* Mean absolute deviation penalizes each distance equally
* Quantiles (Or percentiles)
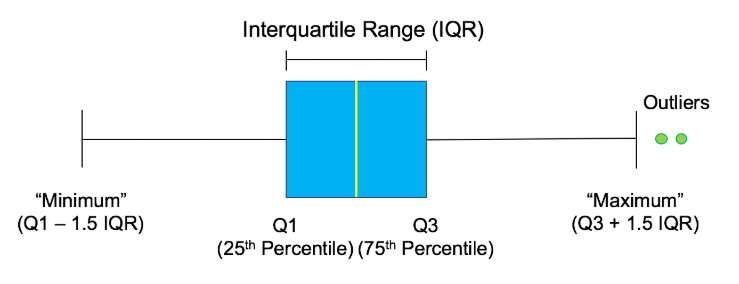
* Interquartile range (IQR)
* Height of the box in a boxplot
* Outliers
* Data point that is substantially different from the others
#### Quartiles, quantiles, and quintiles
Quantiles are a great way of summarizing numerical data since they can be used to measure center and spread, as well as to get a sense of where a data point stands in relation to the rest of the data set. For example, you might want to give a discount to the 10% most active users on a website.
In this exercise, you'll calculate quintiles which split up a dataset into 6 pieces.
```
Q-6) Calculate the quintiles of co2_emission
print(np.quantile(missing part, np.linspace(0, 1, 6)))
You only need to fill in the missing part.
```
```
#Check if you did it correctly
[ 0. 3.54 11.026 25.59 99.978 1712. ]
```
**Variance and standard deviation**
Variance and standard deviation are two of the most common ways to measure the spread of a variable, and you'll practice calculating these in this exercise. Spread is important since it can help inform expectations. For example, if a salesperson sells a mean of 20 products a day, but has a standard deviation of 10 products, there will probably be days where they sell 40 products, but also days where they only sell one or two. Information like this is important, especially when making predictions.
Q-7) Calculate the variance and standard deviation of co2_emission
for food_categories
Q-8) Create histogram of co2_emission for food_category 'beef'
```
#Check if you did it correctly
var std
food_category
beef 88748.408132 297.906710
dairy 17671.891985 132.935669
eggs 21.371819 4.622966
fish 921.637349 30.358481
lamb_goat 16475.518363 128.356996
nuts 35.639652 5.969895
pork 3094.963537 55.632396
poultry 245.026801 15.653332
rice 2281.376243 47.763754
soybeans 0.879882 0.938020
wheat 71.023937 8.427570
```
#### Finding outliers using IQR
This is not homework but additional insight. Please carefully observe the steps.
Outliers can have big effects on statistics like mean, as well as statistics that rely on the mean, such as variance and standard deviation. Interquartile range, or IQR, is another way of measuring spread that's less influenced by outliers. IQR is also often used to find outliers. If a value is less than Q1−1.5×IQRQ1−1.5×IQR or greater than Q3+1.5×IQRQ3+1.5×IQR, it's considered an outlier.In this exercise, you'll calculate IQR and use it to find some outliers.
```
emissions_by_country = food_consumption.groupby('country')['co2_emission'].sum()
print(emissions_by_country)
```
```
country
Albania 1777.85
Algeria 707.88
Angola 412.99
Argentina 2172.40
Armenia 1109.93
...
Uruguay 1634.91
Venezuela 1104.10
Vietnam 641.51
Zambia 225.30
Zimbabwe 350.33
Name: co2_emission, Length: 130, dtype: float64
```
```
q1 = np.quantile(emissions_by_country, 0.25)
q3 = np.quantile(emissions_by_country, 0.75)
iqr = q3 - q1
# Calculate the lower and upper cutoffs for outliers
lower = q1 - 1.5 * iqr
upper = q3 + 1.5 * iqr
# Subset emissions_by_country to find outliers
outliers = emissions_by_country[(emissions_by_country > upper) | (emissions_by_country < lower)]
print(outliers)
```
```
country
Argentina 2172.4
Name: co2_emission, dtype: float64
```
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://pycoders-nl.gitbook.io/pycoders-handbook/~/changes/x6NQQZBuicYZ8pmALkrC/maths-stats/assignment.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.